
Computervisie in precisielandbouw: een combinatie van twee werelden?
“They can have the world. We’ll create our own.”
– The Lion King, 1994

Hier wordt door sommigen een belangrijke rol toebedeeld aan precisielandbouw, een sector die tracht om landbouwsystemen te ontwikkelen en te optimaliseren. Hierbij streeft men naar het toepassen van de juiste teeltmaatregel op de juiste plaats op het juiste moment. In deze sector werd de laatste jaren sterk geïnvesteerd in de verzameling van data om onderzoek te kunnen doen naar systemen die aan dat globale probleem tegemoet kunnen komen.
Kortom, er wacht een enorme hoeveelheid onontgonnen data in de landbouw. Om deze datastromen de baas te kunnen, zal er een versnelling hoger geschakeld moeten worden door het gebruik van innovatieve analysetechnieken zoals artificiële intelligentie. Er is nood aan een combinatie van twee werelden: die van de computerwetenschappen en die van de landbouw.
Artificiële intelligentie: kan het de wereld helpen?

Artificiële intelligentie is niet meer weg te denken uit onze leefwereld (spraakassistentie, zoekmachines…). In vele gevallen gaat het echter nog om relatief eenvoudige applicaties die simpele taken uitvoeren, waarbij veel en duidelijke data wereldwijd beschikbaar is. In de landbouwsector moet de data voornamelijk zelf verzameld worden en kent deze bovendien een sterke natuurlijke variabiliteit, eigen aan de biologische aard ervan. De enorme variatie in onder meer gewassen en omgevingsfactoren is bijgevolg een belangrijk obstakel in het ontwerp van robuuste systemen.
In deep learning, een recente tak van artificiële intelligentie, wordt er automatisch gezocht naar patronen op basis van een ‘bijleer’ mechanisme. De meest voorkomende vorm hierbij is het gesuperviseerd leren, waarbij tijdens het trainingsproces voorbeelden aan de machine getoond worden om de computer correcte voorspellingen te leren maken. Hierbij is het weliswaar vereist om grote hoeveelheden data te labelen om als voorbeeld te kunnen dienen, een proces dat dan wel weer een knelpunt creëert op vlak van specifieke domeinkennis: een kost- en tijdrovende taak.
Veel taken in de precisielandbouw maken gebruik van deze gesuperviseerde methodes, zo kan bijvoorbeeld bepaald worden of de bloemkool juist of omgekeerd ligt op de transportband of kunnen kevers in planten gedetecteerd worden op basis van fotomateriaal en de intelligentie van de computer.
Semi-gesuperviseerd werken: tijd- en kostenbesparend?
Het grote nadeel is uiteraard dat het tijd kost om telkens alles een label toe te kennen. Onderzoek naar methoden die dit kan reduceren staat in de precisielandbouwsector nog in de kinderschoenen. De methode die hier wordt voorgesteld tracht planten te detecteren in grote overzichtsfoto’s van landbouwvelden, gemaakt door drones, op een semi-gesuperviseerde manier: enkel en alleen de noodzakelijk stukjes afbeelding worden gelabeld. Op die manier werd getracht een zo algemeen bruikbaar en overdraagbaar mogelijk basissysteem te ontwikkelen.
Het vooropgestelde probleem werd bekeken vanuit de hoek van anomaliedetectie. Bij anomaliedetectie beoogt men de afwijkende elementen op te sporen en is er sprake van een sterk ongebalanceerde dataset. In dit opzicht worden de planten gezien als afwijkingen ten opzichte van de gevarieerde achtergrond. Door de detectie van planten te bekijken vanuit deze invalshoek, wordt in de methode gebruik gemaakt van een autoencoder als netwerk, een techniek uit de deep learning.
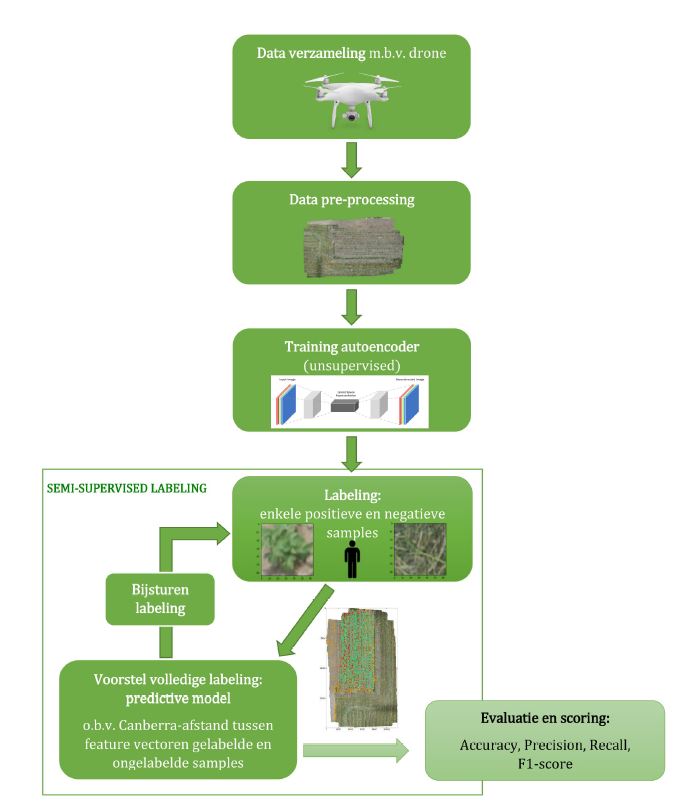
In een eerste stap, de training van de autoencoder, wordt de overzichtsfoto in kleine deeltjes (monsters) als input gegeven aan het netwerk. Deze worden vervolgens gereduceerd tot een eigenschappen-vector door het netwerk om daarna op basis hiervan de afbeelding terug te reconstrueren. Het voordeel hierbij is dat het netwerk dus autonoom de interessante kenmerken selecteert (niet-gesuperviseerd).
In een tweede stap worden enkele monsters uit de afbeelding geselecteerd voor labeling, dit in tegenstelling tot een complete labeling zoals bij het gesuperviseerd werken. De geselecteerde monsters bevatten zowel planten als achtergrond, met als bedoeling de variatie in de afbeelding zoveel mogelijk te dekken. Deze gelabelde monsters worden door de autoencoder gestuurd, waaruit hun bijhorende eigenschappen-vector gehaald wordt. Op die manier wordt een representatieve set van positieve en negatieve eigenschappen-vectoren opgebouwd. Deze eigenschappen-vectoren worden gebruikt om correlaties te ontdekken.
Om vervolgens te bepalen welke monsters al dan niet planten bevatten, wordt tenslotte een eigenschappen-vector bepaald door de volledige afbeelding (per monster) opnieuw door de autoencoder gestuurd. Met behulp van de Canberra afstandsformule wordt de mate van (on)gelijkheid tussen de eigenschappen-vector en alle eigenschappen-vectoren uit de representatieve set berekend. De minimale afstand en dus grootste gelijkheid tot één van deze representatieve samples bepaalt tot welke categorie dat monster gerekend wordt. Op basis hiervan wordt elk monster dus al dan niet geclassificeerd als plant.
Het idee van deze stap is om een applicatie te bouwen waarbij de landbouwer zijn expertise kan gebruiken om kleine stukjes van het veld te labelen. Vervolgens zal het systeem een volledige classificatie suggereren, waarbij de landbouwer indien gewenst kan bijsturen op eenvoudige wijze.
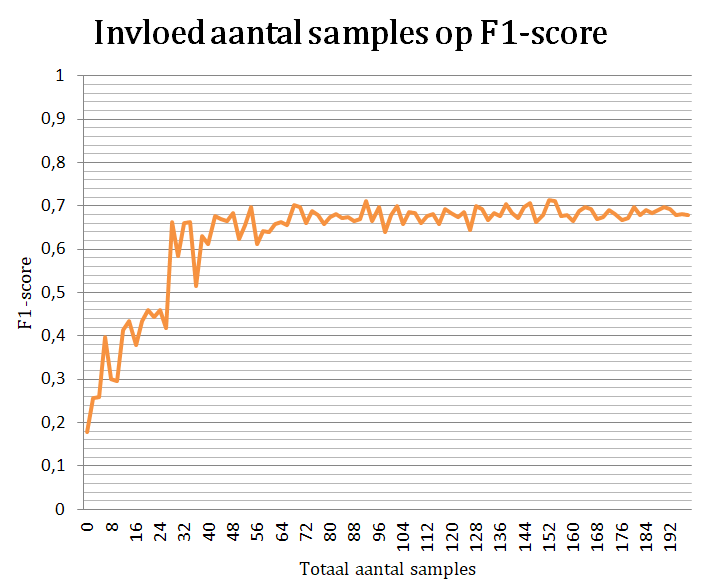
Aangezien deze methode steunt op het idee van minimalisatie van de menselijke interventie, werd ook onderzocht wat het effect is van het aantal gelabelde monsters op de accuraatheid. Hieruit bleek dat de invloed van het aantal stagneert bij zo’n 35 monsters per categorie. Deze grens suggereert dat een extra labeling in deze methode niet resulteert in betere resultaten.
De toekomst?
De procedure zoals voorgesteld in dit werk tracht dus planten te detecteren met een beperkte menselijke interventie. Dit kan in een volgende fase gebruikt worden om onkruiden of zieke planten te detecteren. In de toekomst kunnen intelligente landbouwsystemen ontwikkeld worden die dit automatiseren tot bijvoorbeeld mechanisch wieden in plaats van milieubelastende gewasbeschermingsmiddelen te gebruiken. Want, wees nu eerlijk, een nieuwe fysieke wereld maken is onmogelijk. Wordt het niet tijd om in deze wereld te investeren?







