
Kan je een computer leren grappig te zijn?
Artificiële intelligentie laat toe om steeds meer jobs te automatiseren. Dat leidt tot onzekerheid in een heel aantal sectoren. Creatieve jobs worden desalniettemin vaak als veilig aanzien. Stel u voor dat we Philippe Geubels zouden vervangen door een echte robot. Absurd! Wat als we u echter zeggen dat computers al in staat zijn om half zo vaak grappig te zijn als mensen?
Robotkomieken
We gebruiken computers tegenwoordig met grote regelmaat om mopjes en memes op te zoeken en uit te wisselen met vrienden. Elk van deze berichten wordt momenteel door mensen gemaakt. De vraag stelt zich of onze dagelijkse dosis internethumor ooit van de hand van een computer zou kunnen komen. Kan een robotkomiek dan ook gepersonaliseerde mopjes voor en over zijn gebruiker maken? En zijn die mopjes dan überhaupt wel grappig?
In deze thesis onderzochten we de mogelijkheid om met computers mopjes te genereren, en dit door middel van het automatisch analyseren van bestaande moppen. Er bestaan reeds enkele programma’s die één bepaald soort humor kunnen produceren, door bijvoorbeeld simpele woordspelingen te construeren of door te weten na welke zinnen het passend is om “That’s what she said!” uit te printen. De kennis over het gekozen type humor werd echter steeds door onderzoekers handmatig gemodelleerd. In ons onderzoek construeerden we echter een framework dat in staat is om uit een verzameling moppen te leren hoe het zelf soortgelijke grappen kan genereren. Met dat systeem genereerden we honderd moppen die vervolgens door honderden vrijwilligers werden beoordeeld. Het resultaat? De gegenereerde mopjes werden 11,4% van de tijd als grappig aanzien, terwijl de mopjes van vrijwilligers 22,6% van de tijd grappig werden bevonden.
Computationeel gevoel voor humor
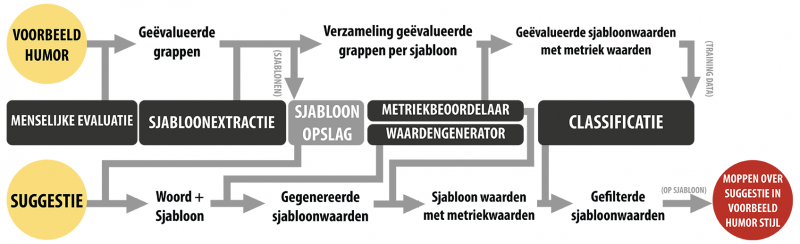
In het onderzoek leert het computerprogramma eerst scores toe te kennen aan mopjes. Daarna zoekt het de pareltjes in miljoenen willekeurige mopjes. Om het programma zulk gevoel voor humor te geven, laten we het eerst een grote verzameling tekstuele mopjes bekijken met bijbehorende beoordelingen. Leeralgoritmes werken echter liever met getallen dan met teksten van variabele lengte, zoals mopjes. Het programma detecteert daarom eerst grote gemeenschappelijke stukken tekst in de mopjes, en slaat die op als sjablonen. Een voorbeeld van een mogelijk sjabloon is “Ik hou van mijn X zoals ik hou van mijn Y: Z”. Een mogelijke woordinvulling voor X is dan “koffie”, voor Y “oorlog” en voor Z “koud”. Die stap zorgt ervoor dat de computer enkel nog met een vast aantal geselecteerde woorden per sjabloon moet werken.
Om het programma dan uit de geselecteerde woorden te laten leren, moet het die omzetten naar een reeks getallen. Daarvoor zijn maatstaven nodig: dat zijn functies die een of meerdere woorden transformeren naar een getal. In de thesis analyseren we verschillende humortheorieën en identificeren we zo een verzameling potentiële maatstaven. Een voorbeeld van een maatstaf is de frequentie waarmee een adjectief voorkomt om een substantief te beschrijven, om zo te benaderen hoe sterk bepaalde woorden bij elkaar horen. Deze maatstaven transformeren de geselecteerde woorden naar een verzameling getallen. Die getallen worden dan verwerkt met statistische technieken om te leren inschatten hoe goed een mop is. We verkregen het beste resultaat wanneer het programma de meest voorkomende beoordeling (1 tot 5 sterren) moest raden. Voor de voorbeeldmoppen kon het programma die taak de helft beter dan de vrijwilligers. Onze robotkomiek tracht op die manier dus een groot aantal toeschouwers hard te laten lachen, eerder dan alle toeschouwers een beetje te laten lachen.
JokeJudger
Ons systeem heeft nood aan een grote verzameling moppen als voorbeeldmoppen, liefst van hetzelfde type. We kozen voor grappige vergelijkingen in de vorm “I like my X like I like my Y: Z.” als type. Daarna creëerden we het platform JokeJudger.com, waar gebruikers zulke mopjes kunnen creëren en beoordelen. Dat platform gebruikten we zowel voor het verzamelen van de voorbeeldmoppen als om de gegenereerde moppen op het einde van het onderzoek te beoordelen. We verzamelden op dit platform een dataset van 203 gebruikers, 9 452 beoordelingen en 524 mopjes.
Automatische grappenselectie
Eens het algoritme getraind is op de verzamelde mopjes, is het in staat om uit grote hoeveelheden willekeurige moppen de beste te selecteren. Het programma genereert miljoenen mogelijke invullingen voor grappige vergelijkingen in de vorm “I like my X like I like my Y: Z”, waarbij X en Y substantieven zijn en Z een adjectief dat zowel bij X en Y past. Daarna selecteert het programma met zijn net aangeleerde gevoel voor humor de mopjes die volgens zijn inschattingsvermogen hoge scores zouden krijgen. Op die manier genereert het systeem dus goede moppen in een vorm gelijkaardig aan de gegeven voorbeeldmoppen.
Voordelen
Aangezien het systeem werkt voor meerdere soorten humor en automatisch nieuwe soorten moppen kan leren, generaliseert en verbetert onze methode het leeuwendeel van het bestaande onderzoek in computationele humor. Ook kan het systeem zich aanpassen aan specifieke gebruikers, door enkel hun beoordelingen te gebruiken in het leerproces en zo gepersonaliseerde moppen te genereren. Een ander voordeel is dat het programma in staat is te leren uit zijn eigen missers en voltreffers bij het publiek.
Bij het evalueren door honderden vrijwilligers vonden we dat grappige vergelijkingen gegenereerd door ons systeem 11,4% van de tijd als grappig werden ervaren. Mopjes afkomstig van onze vrijwilligers waren 22,6% van de tijd grappig. Gezien we een significant groot aantal beoordelingen (bijna tienduizend) verzameld hebben, kunnen we hieruit besluiten dat ons systeem al half zo vaak als grappig wordt ervaren als een doorsnee mens.
Dit jaar ziet u waarschijnlijk nog steeds Philippe Geubels – geen robot – weer op de planken. Maar aangezien de mopjes van het systeem in ons onderzoek al één kans op negen hebben om grappig te zijn, kunnen dergelijke systemen komieken wel helpen met het schrijven van hun teksten. Ook opent dit onderzoek de deur naar meer menselijke versies van Siri en Google Assistant, die hiermee net als echte vrienden kwinkslagen in hun antwoorden kunnen verwerken.







