
Het Sentiment van Limburg
(zie bijlage voor opgemaakte versie in pdf-formaat)
Mediahuis Connect doet zijn krant Het Belang van Limburg uit de doeken als grootste en populairste krant in de provincie Limburg. Met hun nieuws bereiken ze maar liefst 85% van de Limburgse krantenlezers. Aangezien nieuwsbladen sterke spelers zijn bij het vormen van de publieke opinie, is het interessant om de impact van de nieuwsartikels van HBVL op de Limburger onder de loep te nemen. Met behulp van de reacties die geplaatst worden op hun Facebookpagina kan het sentiment van de lezer nu automatisch geanalyseerd worden.
Om hun lezers nog sneller te kunnen bereiken plaatst HBVL dagelijks meerdere artikels op hun Facebookpagina. Aangezien er een constante stroom aan reacties op deze artikels is, is het onbegonnen werk deze allemaal met de hand te analyseren. In een wereld waar computers ons heel wat rekenwerk uit handen nemen, kan gezocht worden naar methodieken om automatisch het sentiment van de reacties te voorspellen. Er worden hierbij twee belangrijke taken uitgevoerd. Enerzijds wordt achterhaald hoe het sentiment uit korte Nederlandstalige tekstjes kan worden afgeleid. Dit proces wordt aangeduid als Natural Language Processing. Met de informatie die hieruit verkregen is wordt de tweede taak uitgevoerd: leren! De computer gaat zichzelf trainen en leren hoe hij uit de informatie het sentiment van reacties kan voorspellen. Dit is het domein van Machine Learning.
Drie sentimenten
Het analyseren van het sentiment houdt in dat voorspeld wordt of een reactie een positieve, negatieve of neutrale connotatie heeft. Dat een artikel voornamelijk negatieve reacties uitlokt is niet noodzakelijk slecht. Dit hoeft niet te betekenen dat een lezer ontevreden is over de inhoud van het artikel. Ook reacties die een vorm van medeleven uiten worden als negatief geclassificeerd aangezien de lezer hiermee aangeeft droevig te zijn. Ook andersom kan gesteld worden dat een positieve reactie niet altijd goed bedoeld is.
Schrijffauten...
Chattaal, vreemde zinsbouw, het ontbreken van leestekens en schrijffouten zijn op sociale media schering en inslag. Zodoende zijn ook de reacties die op de artikels van HBVL’s Facebookpagina geplaatst worden hier sterk aan onderhevig. Bepaalde woorden kunnen echter een sterke invloed hebben op het uitgedrukte sentiment. Daarom is het belangrijk om fouten op te sporen zodat verkeerd gespelde woorden eveneens als hetzelfde woord behandeld worden. Dit kan nog verder worden doorgetrokken door verschillende woordvormen naar hun stam te reduceren. Dit zijn slechts een paar voorbeelden van operaties die vooraf moeten gebeuren. Een goede voorbereiding is het halve werk!
1, 0, 12, 0.75, 0
In tegenstelling tot jij en ik kunnen computers geschreven tekst niet zo goed begrijpen. Daarom moeten de reacties naar een formaat worden omgezet waarmee de computer aan de slag kan. Uit de tekstjes worden numerieke kenmerken afgeleid die van belang kunnen zijn bij het voorspellen van het sentiment. Denk maar aan het aantal voorkomens van bepaalde woorden, de fractie van het bericht dat in hoofdletters staat of het aantal lachende emoji. De mogelijkheden zijn eindeloos! De reactie kan nu woorden voorgesteld als een reeks van getallen.
Verschillende leermethodes
De computer kan op verschillende manieren leren hoe hij met behulp van de gegeven getallen het sentiment kan voorspellen. Hij krijgt eerst veel voorbeelden van reacties waarbij ook telkens het sentiment dat ze uitdrukken gegeven is. Nu moet de computer op zoek gaan naar verbanden tussen de reacties die tot eenzelfde sentiment behoren. Hij kan hiervoor een hiërarchisch schema opstellen, gekend als een Decision Tree, waarin op ieder niveau de waarde van één van de getallen afgetoetst wordt: “Zijn er hoogstens vijf uitroeptekens? Ja? Komt er dan minstens ééns boze emoji voor? Nee? Dan is de reactie vast positief!”
Een andere methode is gekend als een Support Vector Machine waarbij de reacties als punten in een n-dimensionale ruimte geplaatst worden. De computer zoekt waar hij een scheidingslijn kan plaatsen zodat de reacties met eenzelfde sentiment aan dezelfde zijde liggen. Het sentiment voorspellen houdt dan in dat de computer kijkt aan welke kant van de scheidingslijn de reactie ligt. Een derde methode is om de kans te bereken dat een reactie met diens kenmerken tot elk van de sentimenten behoort. Een bekende techniek hiervoor heet Naive Bayes.
Stel je voor! 34 jaar lang leren...
Ongeacht de gekozen leermethode geldt: hoe meer voorbeelden, hoe liever. Voor dit onderzoek zijn 500 positieve, 500 negatieve en 500 neutrale reacties verzameld. De kwaliteit van de voorspellingen kunnen verbeterd worden door te puzzelen met combinaties van interessante kenmerken van de reactie en deze telkens te testen met verschillende leermethodes. Er zijn echter ontzettend veel combinaties mogelijk. Zo veel zelfs, dat het 34 jaar zou duren om ze allemaal op één computer te testen. Door echter op een slimme manier te zoeken naar een zo hoog mogelijke accuraatheid is een voorspeller gevonden die 73,7% van de reacties correct kan voorspellen. Een resultaat waarbij gebruik is gemaakt van Naive Bayes en die de vooropgestelde verwachtingen heeft overtroffen.
Webtool
Om de bekomen voorspeller in de praktijk te kunnen gebruiken is de webtool Het Sentiment van Limburg ontwikkeld. Deze toont de artikels die geplaatst zijn op de Facebookpagina van HBVL. Per artikel kunnen de reacties getoond worden waarbij tevens aangeduid is in welke mate de reactie tot ieder sentiment behoort. Dit is met een taartdiagram gevisualiseerd waarbij groen de graad aangeeft dat de reactie een positief sentiment uitdrukt, rood de graad van het negatief sentiment en blauw dat van het neutrale sentiment. Ook per artikel wordt met een taartdiagram de verdeling weergeven van de sentimenten van de bijbehorende reacties.
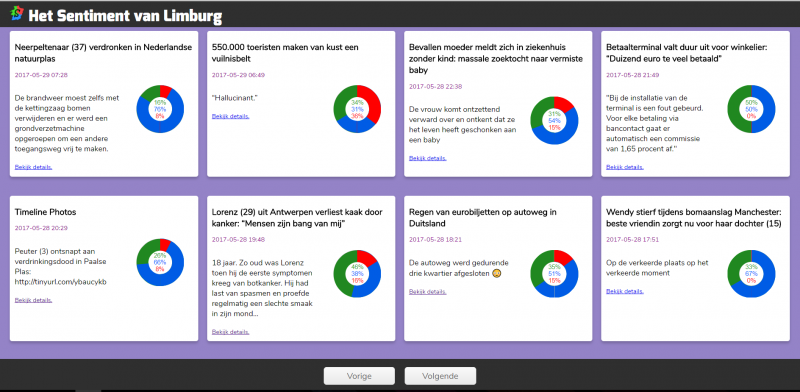
Met het oog op geautomatiseerde sentimentanalyse van nieuwsartikels is er een brede waaier aan leermethodes mogelijk. Het is eveneens van groot belang om aandacht te hebben voor het afleiden van relevante kenmerken die in de reacties verscholen zijn. De webtool Het Sentiment van Limburg maakt gebruik van een voorspeller die er in slaagt het sentiment van 73,7% van de reacties correct te voorspellen. De resultaten worden in deze tool gevisualiseerd zodat ze gebruikt kunnen worden om de impact van de nieuwsartikels verder te onderzoeken. Zouden we binnenkort ook op voorhand op basis van een artikeltitel het sentiment kunnen voorspellen?







